Objective: To provide a reader with an overview of how we approach the challenge of link rot within the parameters defined by the author and arrive at a high-level workflow that will form the basis of a solution architecture.
Table of contents
№01. [What is Link Rot?](#section1-what_is_link_rot)
№02. [Types of Content and Sources Affected by Link Rot](#section2-content-source-types)
№03. [Framing the Challenge - High-Level Considerations](#section3-high-level-considerations)
№04. [Existing Solutions To the Challenge](#section4-existing-solutions)
№05. [Identifying Requirements - What are the “Nice to Have’s”](#section5-solution-requirements)
№06. [Architecting a Solution](#section6-solution-workflow)
While problem is pretty well defined on external sites (eg: Wikipedia), to me, link rot quite simply translates to - not being able to access the information and/or content one needs at point 1 from a resource that was on the web during point 0 (where point [0, 1,..n] are incremental units of time eg: days, weeks, months, years).
This could be because of a number of factors including (but not necessarily limited to):
Site structural changes without adequate redirection to new links
Takedown notices requiring the content or website to go offline
Domain and/or Service Provider expiry and non-renewal
Types of Content and Sources Affected by Link Rot
#
Link rot affects us on multiple fronts for a variety of different content types.
We can frame the link rot challenge as a combination of the following (though not necessarily limited to) source and content types:
Framing the Challenge - High-Level Considerations
#
Before attempting to architect any solutions, this section of the document will help frame the challenge at hand when it comes to link rot. While this frame may not be all encompassing, it is personalized and thus is based on current requirements.
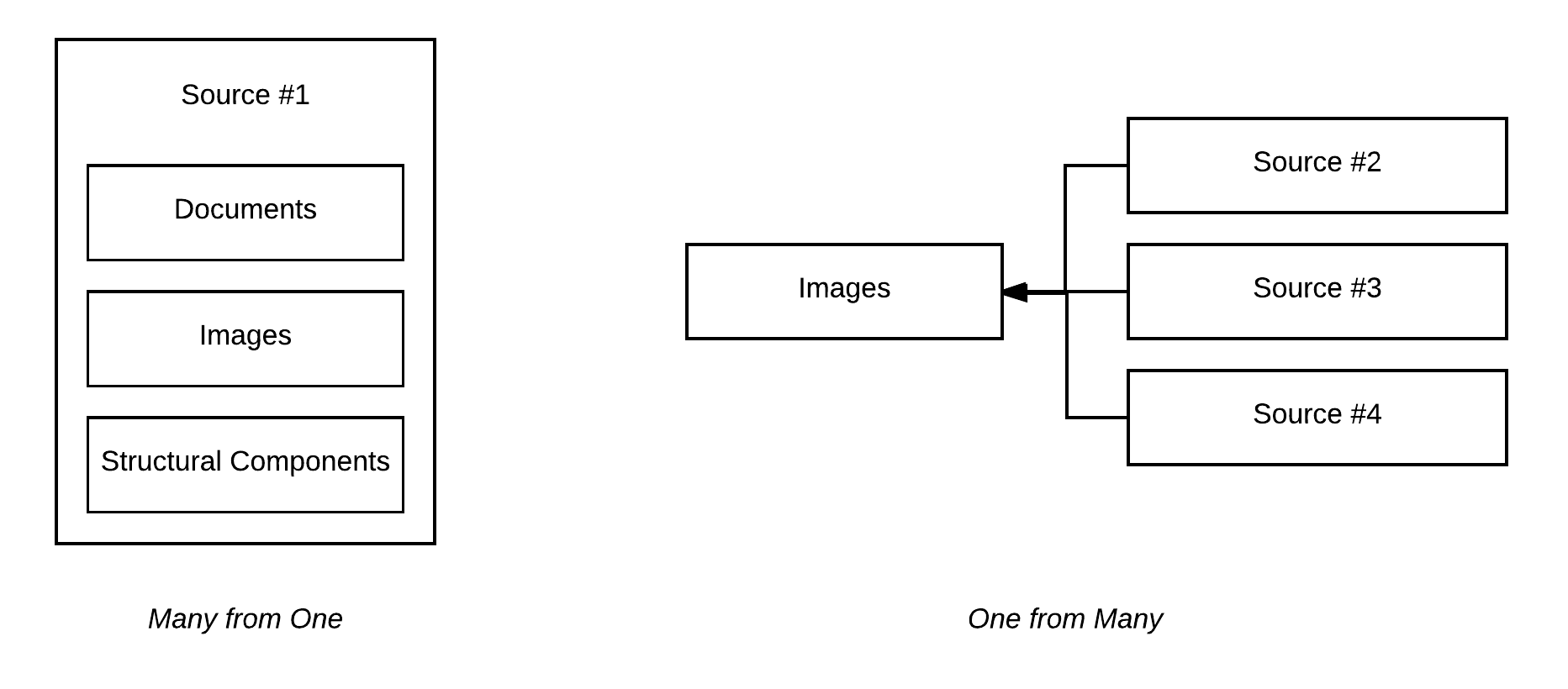
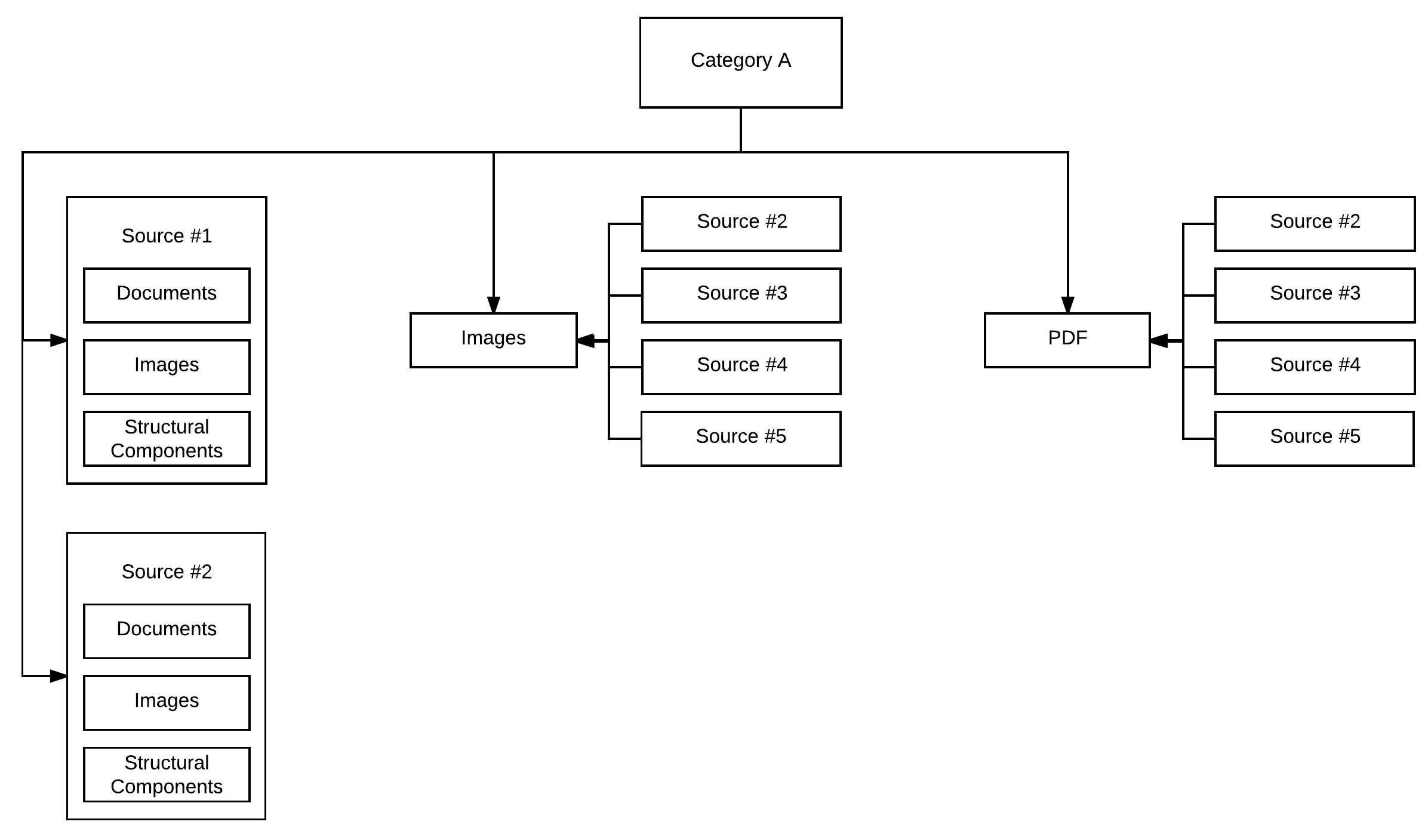
Sources with multiple content-types and specific content types derived from multiple sources need to be classified into buckets based on the niche and/or category to enable easier retrieval of content at a later date.
This can be visually thought of as follows:
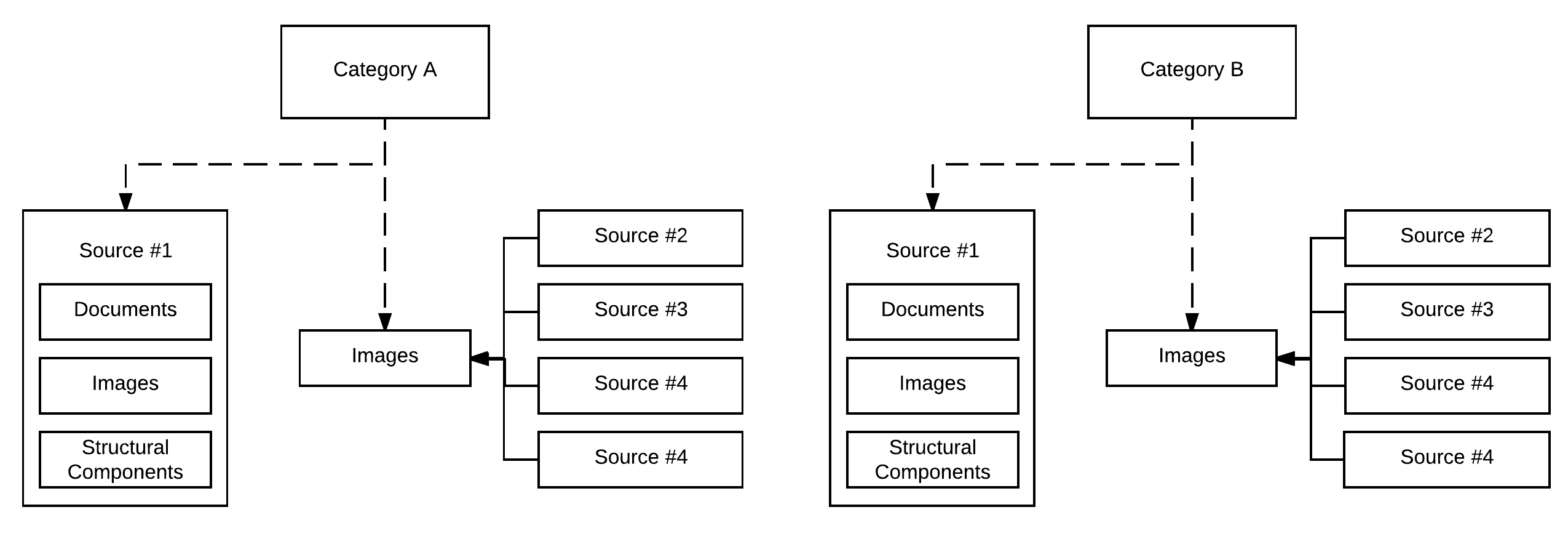
Given that each category obviously comprises of multiple sources of content-types, the visualization above can be easily extended to the following as a means of better representing the state of the challenge:
There are three other key components to the above, which are:
Time
Access Control
Storage
At a high-level the considerations for each of those are as follows:
Time
Does the source (Many from One) stay the same over time?
How often do we archive the sources and content-types?
Does our frequency affect the source? (eg: Bandwidth and Server Resource Constraints)
Access Control
Who has access to the archive?
Can the information collected be shared either privately to elected individuals or publicly on the net?
Should it be made available in alternate formats to the aforementioned parties (identified or otherwise) ?
Do the archives detract users from visiting the primary source? Does this violate any usage and/or consumption policies?
Storage
How do we store the collected archives? Are there any limitations? Are there any efficiencies that can be achieved? (eg: Compression)
How do we access the stored archives? Are there multiple and/or different ways to browse the archives based on the content and/or source type?
Do the access controls above translate to the storage of the content as well?
The three additional considerations above will be explored through the solutions below to better demonstrate how one can achieve the above based on the solution(s) elected.
Before proceeding to architect a new solution for the challenge, it is important to scope out and identify solutions that may already address the needs and requirements of the challenge above and possibly outline where it doesn’t completely fit the requirements.
There are a few services and/or tools that I’ve discovered (but not extensively tested) that can not only serve as a bookmarking service but a link archival service as well. They do this by creating an offline or archived snapshot of the webpage at time of bookmarking (point 0) which then enables you to go back and refer to the content at a future date (point 1..n).
The tools and/or services (that I am aware of) that offer this functionality are as follows:
Web scrapers enable us create complete (or as complete as possible) copies of entire (or elected partial portions of) websites along with all the structural components associated with said site.
Examples of tools and/or services (that I am aware of) that offer this functionality are as follows:
Really efficient for archiving large and/or complete (or partially elected) mirrors of identified resources (‘Many from One’)
Can be configured to perform tasks on an automated basis from a select list of URLs
Identifying Requirements - What are the “Nice to Have’s”
#
This section will aim to cover some of the “nice to have” features for combating link rot. The goal is to potentially highlight requirements that are not readily covered by the tools and/or services above but may possibly be achieved through chaining and/or with some additional code.
“Nice to Have” Requirement List
Automated Archival of Bookmarks and OneTab lists
Ability to operate without relying on local resources (eg: Running on an External Server)
Ability to monitor progress and results of current and past archival activities
Ability to gauge existing storage utilization and potentially chart incremental requirements for archives
Ability to do delta updates on specific targets rather than full archivals
Requirement #1 - Automated Archival of Bookmarks and OneTab lists
#
OneTab is probably my most frequently used add-on. It basically keeps a local copy of tabs that I’ve yet to read or am planning to refer to at a later point in time. The advantage of the add-on is the (virtually) limitless amount of URLs it can store locally. That unfortunately does lead to two challenges for me, which are:
Long lists going back to the date of initialization
Lists are machine and browser-based and do not transfer over to other browsers on the same system and other systems used by the same user (even when the same user profile is used) creating multiple copies of different lists.
NOTE : It is important to note however that this is not a negative criticism at the add-on. I am a HUGE fan of OneTab.
In addition, I occasionally (by force of habit) use either the browser’s native bookmarking feature or the external service offered by Pocket and Evernote. This creates a wide array of disparate collections that aren’t optimal when looking for information or that one article I bookmarked that one time.
Browser bookmarks on the other hand are less of a concern and slightly easier to deal with - especially because they automatically get backed up and are available at a later - more often than not with a robust, searchable index through the ‘Bookmark Managers’ that are built-in.
However - besides the few quick links - it would be great if I could selectively pick a specific folder or two from the bookmarks to be archived especially for offline browsing.
Requirement #2 - Non-reliance on local resources
#
All archival activities need to flexible enough to run either locally on my current machine or remotely on a server of choice. This reduces the requirement of keeping a local machine available with active resources allocated towards archival activities thus enabling both ‘business-as-usual’ and archival activities to function simultaneously.
Requirement #3 - Ability to monitor progress of present activities and past results
#
All automated activities need to be monitored (and tested) in some capacity over the course of their lifespan to ensure that:
It functions as it is intended to
Any new edge cases and/or issues that were not originally accounted for is discovered and subsequently addressed
More importantly monitoring is required to ensure that when an automated process fails - it needs to fail noisily. All monitoring alarm should be triggered to the extent of the seriousness of the fault to ensure that it is registered and subsequently addressed.
Requirement #4 - Ability to gauge existing storage utilization
#
As we scale our archival activities to cover all sources and content types associated with personal link rot, it is important to ensure that one has the ability to assess and plan for storage requirements should one continue to automatically generate incremental full or delta snapshots of said sources.
Requirement #5 - Ability to perform delta updates vs full updates
#
This requirement while optional does directly impact [Requirement #4]. The requirement will be revisited based on the current identified storage options available for the challenge.
This section will aim to demonstrate how we derive an architecture for a solution to the aforementioned challenge. It however does not imply that the process undertaken is explicitly detailed and all encompassing but instead will serve as a guideline to the overarching thought process at hand.
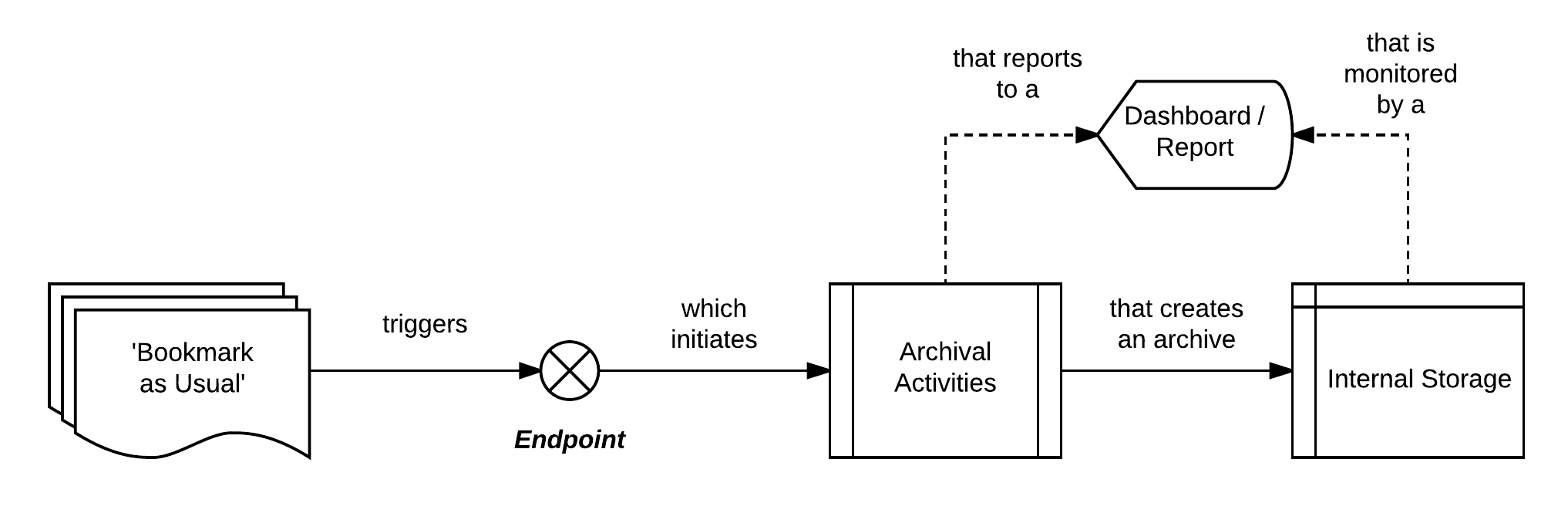
Based on the above, one can already visualize a high-level workflow for an intended solution:
The workflow outline is as follows:
Bookmarks or Target URL lists are created as usual on a local machine and/or elected location eg: File share
An endpoint is triggered at a previously configured interval
The triggered endpoint initiates pre-configured rule-based archival activities
The triggering of the archival activities also initiates log monitoring through a Dashboard or preconfigured report that can be reviewed through a Browser on an External device
Post completion of an archival thread from the overall activity - the result (or files)is stored at an elected and monitored storage solution for retrieval at a later point
The solution can broadly though compressed into three major categories, namely:
Export
Extract
Store
Given that the above, we can start working on the implementation of the solution based on the aforementioned requirements.
The next article in the series will aim to cover the implementation of a case solution based on the above.